REQ Extract AI
REQ Extract AI est un pipeline semi-automatisé d'extraction d'exigences de normes avioniques (ARINC-653, DO-178C) à l'aide de Large Language Models. Ce projet de fin d'études a été réalisé dans le cadre de mon projet de fin d'études à l'École de Technologie Supérieure. Au sein de ce projet, j'ai été chef d'équipe et responsable de l'infrastructure, en charge du déploiement, de l'orchestration des services et de l'intégration des modèles de langage. J'ai partagé ce projet avec Amara Madi Ramzi, Mohamed Rayan Laras, Albert Bryan Ndjeutcha et Melvin Siadous.
Challenge

Les documents avioniques présentent de nombreux défis qui rendent difficile leur exploitation automatique : hétérogénéité du format (texte, tableaux, figures, notes), exigences implicites cachées dans les descriptions, références croisées fréquentes entre sections, et fragmentation du contenu sur plusieurs pages. L'objectif était de concevoir un pipeline robuste capable d'intégrer du nettoyage documentaire, de l'OCR avancé, un découpage par blocs logiques, et un modèle de langage capable de déduire à la fois les exigences explicites et implicites. Il fallait transformer ces normes complexes en exigences structurées et exploitables, tout en conservant une fiabilité compatible avec les contraintes d'ingénierie critique.
Processus
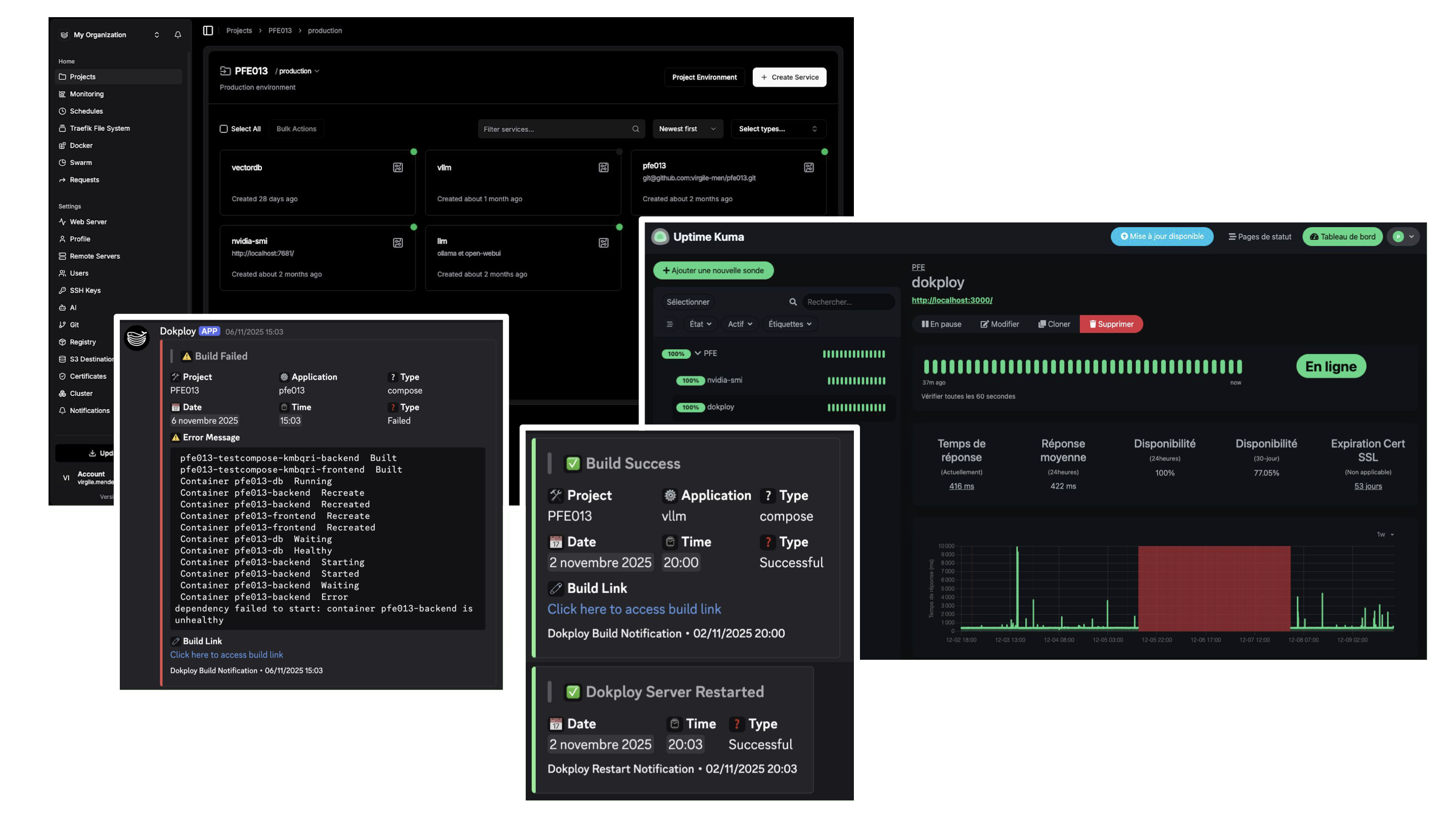
En tant que chef d'équipe, j'ai mis en place une méthodologie agile avec des sprints de deux semaines, un tableau Kanban sur GitHub pour la gestion des tâches, et une communication structurée via Discord, Slack et Zoom. Les rencontres bihebdomadaires avec le client permettaient d'avoir des retours directs et d'ajuster continuellement la feuille de route. Pour l'infrastructure, j'ai déployé l'application sur une machine virtuelle fournie par l'ÉTS. L'architecture conteneurisée avec Docker Compose regroupait le backend FastAPI, le frontend Next.js, PostgreSQL, Ollama pour l'inférence LLM de modèles localement hébergés, et ChromaDB pour la recherche vectorielle. J'ai choisi Dokploy pour le déploiement continu, permettant un déploiement automatique à chaque push sur la branche main avec monitoring via Discord. J'ai également configuré Uptime Kuma pour surveiller la disponibilité de la VM et notifier l'équipe en cas d'incident. Cette infrastructure m'a permis de gérer efficacement les contraintes budgétaires tout en validant la faisabilité conceptuelle du pipeline.
Résultats
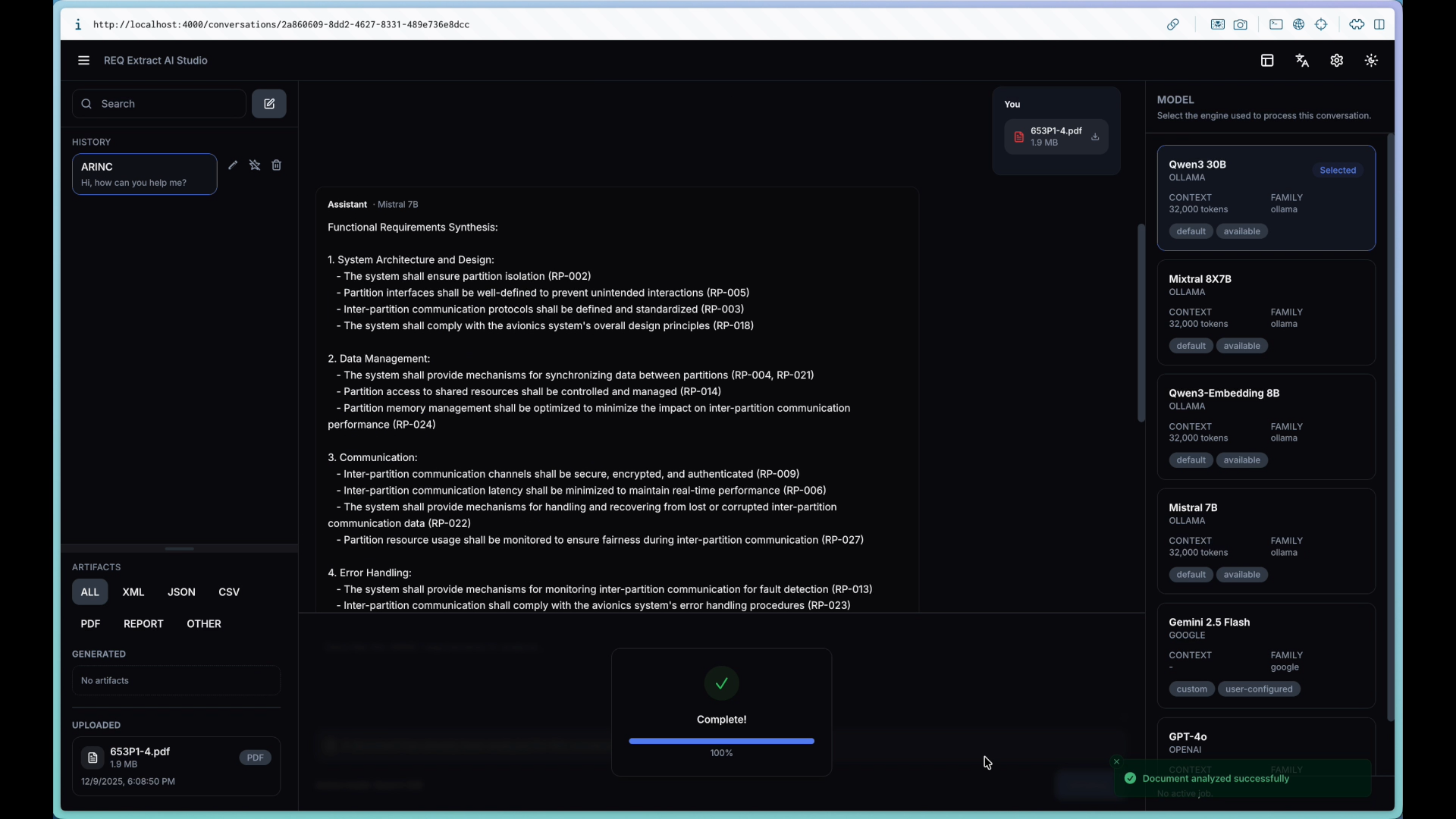
Le projet a permis de développer un pipeline fonctionnel complet : ingestion de PDF, nettoyage, segmentation, extraction via LLM et interface web interactive. Chaque exigence extraite est structurée avec un identifiant, une section source, un type d'exigence, et des champs condition/action/objet. L'outil peut constituer un support utile pour un public débutant en mettant en évidence des phrases candidates et en proposant une structuration initiale. Ce projet m'a énormément appris sur la gestion d'équipe, la communication structurée et surtout sur l'infrastructure DevOps : déploiement continu, monitoring, orchestration de conteneurs, et intégration de modèles de langage. J'ai également approfondi ma compréhension des enjeux techniques associés aux LLM dans un contexte certifiable, explorant des technologies comme ChromaDB, RAG, et l'auto-hébergement de modèles. Malgré les contraintes matérielles et budgétaires, nous avons réussi à concevoir une architecture complète et fonctionnelle qui démontre la faisabilité de l'approche.
Remerciements à Ghizlane El Boussaidi et Ikram Darif.